Snowflake is a cloud-based data platform that enables organizations to store, process, and analyze massive amounts of data with high performance and scalability. It supports diverse workloads—from data warehousing and analytics to machine learning—through a secure, multi-cloud architecture.
This design project focused on building annotation in Document AI, an end-to-end experience that allows business users and data teams to create scalable document-processing pipelines. By converting unstructured files into structured data, Document AI strengthens Snowflake’s core value proposition—making all data queryable, integrated, and ready for AI-driven insights.
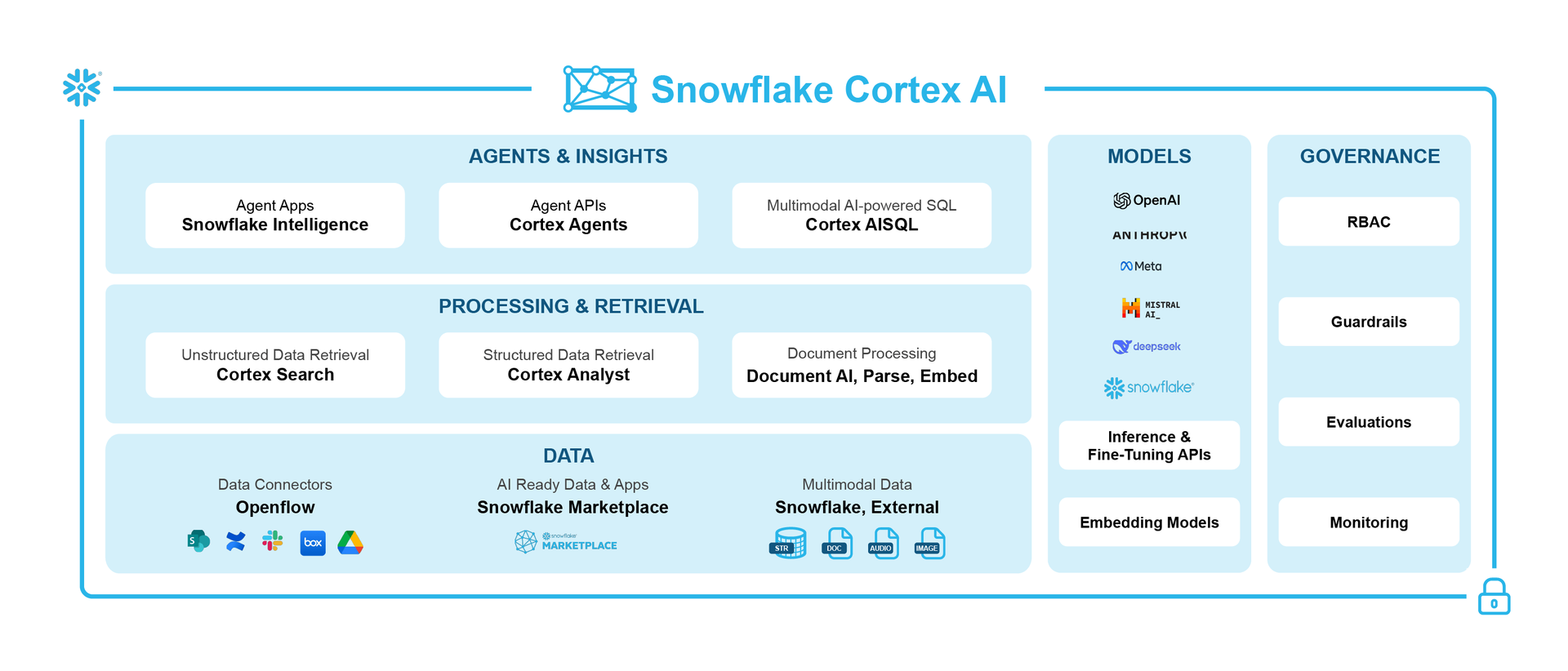
Document AI sits within the processing and retrieval layer of Cortex AI, Snowflake’s AI platform that unifies models, data, and governed execution. Cortex AI powers agent applications, multimodal SQL, retrieval, and orchestration across structured and unstructured data.
Within this ecosystem, Document AI plays a focused but essential role: transforming vast volumes of diverse documents—such as invoices, forms, and contracts—into accurate, structured, and queryable data with minimal setup.
This capability enables enterprises to seamlessly integrate document-derived insights into Cortex-powered applications, retrieval workflows, and downstream AI use cases, advancing Snowflake’s mission to make all data usable and AI-ready.
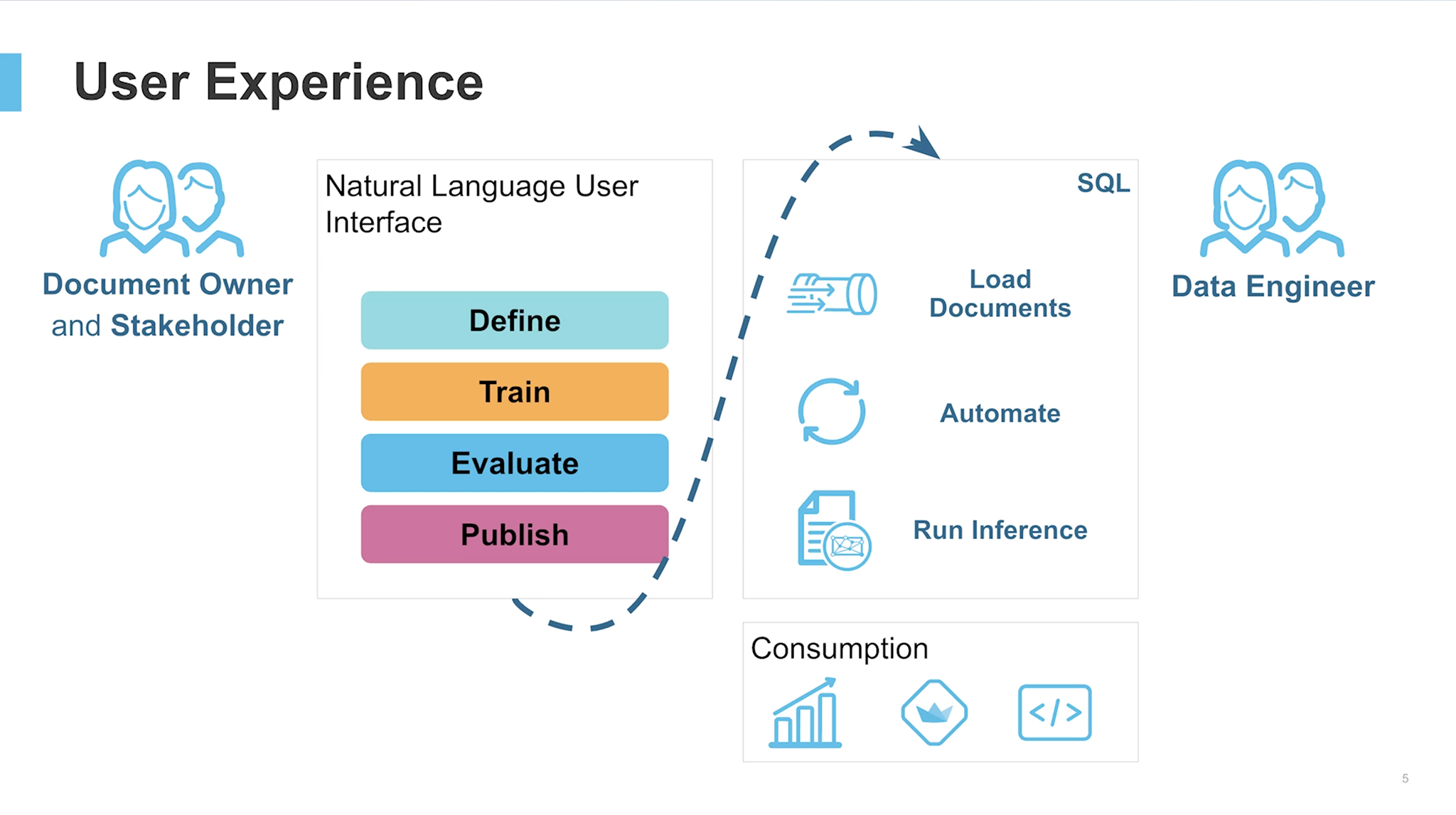
Working with Document AI follows a streamlined two-phase journey. First, users create a model build representing a specific document type. They upload sample files, define extraction targets by simply asking natural-language questions, and validate results across roughly 15–20 documents.
With minimal effort, the model learns patterns unique to the use case and can be fine-tuned for higher accuracy. Once published, the model can reliably extract information from billions of documents using prediction queries. These queries can then power automated pipelines with streams and tasks, enabling continuous, scalable document processing across enterprise workloads.

Annotation is not the core objective of the workflow, but it plays a crucial supporting role in enabling accurate validation of the model’s zero-shot answers. Users must confirm whether extracted values are correct before scaling the model to billions of documents.
While 80% of files range from one to five pages, the remaining long-tail—up to 200 pages—creates significant challenges in navigation, clarity, and cognitive load. Therefore, designing an efficient annotation experience becomes essential. Streamlining this step helps users validate quickly and confidently, directly improving model quality and the overall reliability of large-scale document processing.

1. Enable users to easily organize their extractions
2. Assist users in locating the references for the answers from the documents
3. Facilitate user navigation within long documents

